最近我在为 Eidos 实现一个类似 Notion/Obsidian 的 Publish 服务,用户可以将自己的 space 发布到互联网上公开。做了很多的技术尝试,也体验了很多云服务,这篇讲下心路历程。
在 Eidos 中,每个空间(space)都可以独立导入和导出,不会像 Notion 那样自己导出的东西,导不回去。这种设计类似于 Obsidian 的 vault。导出的 space.zip 文件结构很简单,包含一个 sqlite 文件和一个 files 目录。sqlite 文件中存储了所有用户数据,包括文档、表格、扩展等,而 files 目录则存储了图片等静态资源。
# eidos-export-<space-name>.zip
- files
- a.jpeg
- b.wav
- ...
- db.sqlite3
发布服务的实现也很简单,将 files 传到 R2。sqlite 文件上传到 sqlite 云服务。然后整个 SPA build 成只读模式,通过 *.eidos.ink 的域名访问,通过一层 worker 中转,静态资源走 R2,数据查询走 sqlite 云服务。
本地离线版本实现 eidos.space
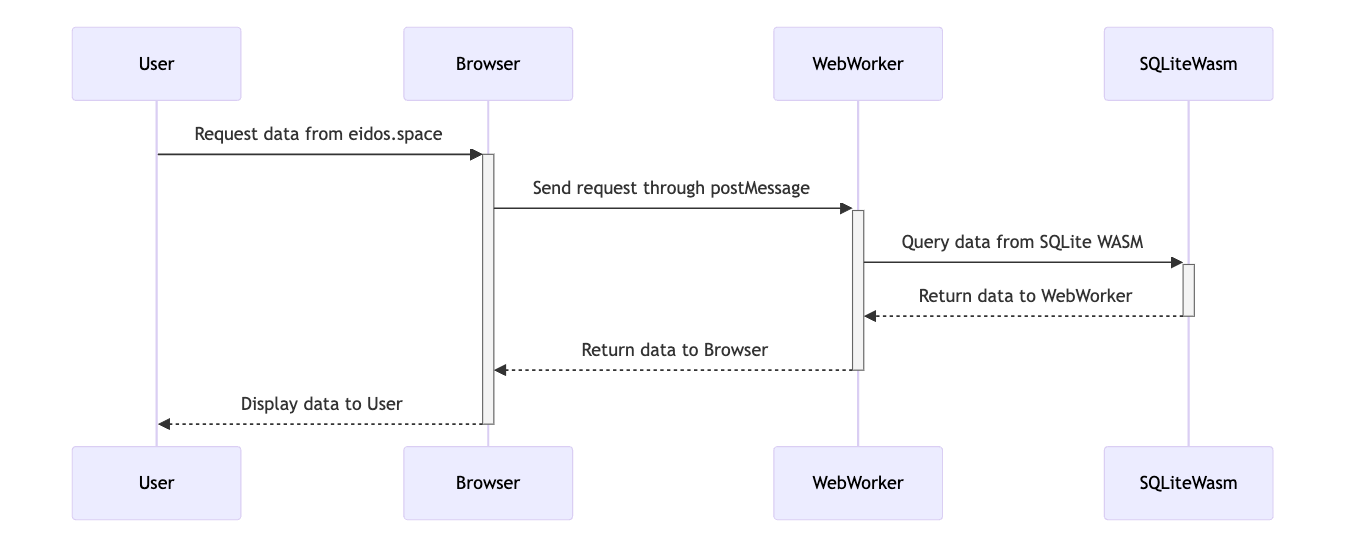
Publish 服务实现 *.eidos.ink
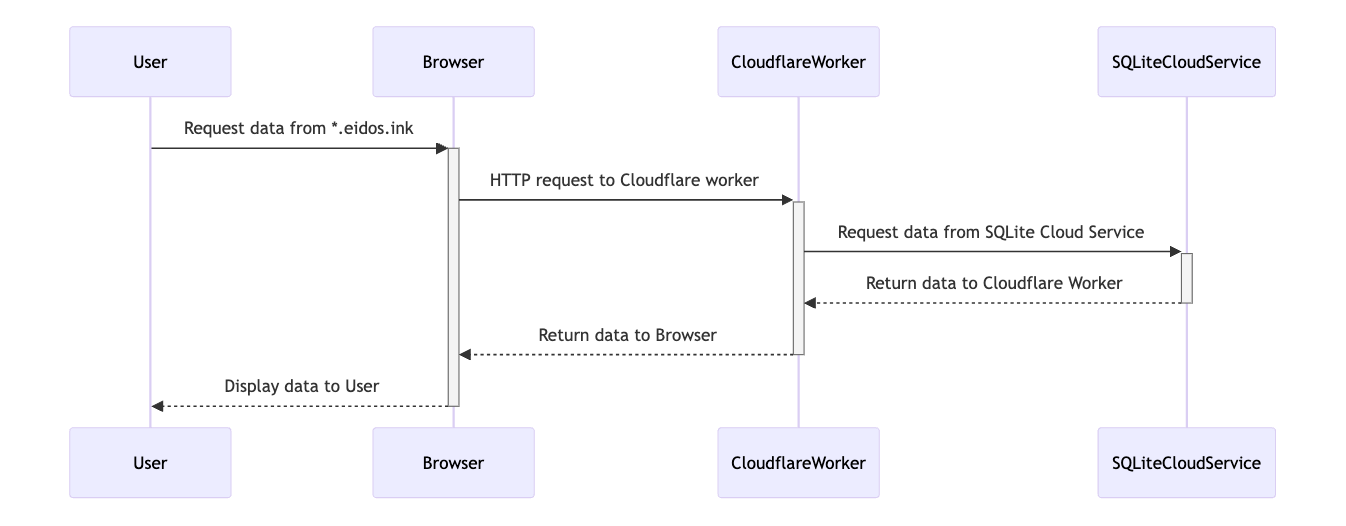
可以看到 publish 服务和离线的 app 是非常相似的实现,cloudflare worker 遵循 web worker 的标准,因此很多代码都不太需要改动,只需要做少许的适配,整体服务就能玩转起来。完事具备,只缺一个 sqlite 云服务。
Turso 和 D1
Turso 最开始是做 libsql 的,一个 sqlite 的 fork 实现。sqlite 的代码版权流入公共领域,是完全的开源,但是作者因为版权问题太头疼,不开放社区贡献。libsql fork 了 sqlite,做了一些实用性的改进和创新,这里不讨论。turso.so 是其提供的商业化云服务,SQLite for production 这句描述得很准确。
我部署了一个香港的节点,整体效果非常棒,唯一的缺点是“太贵”了。
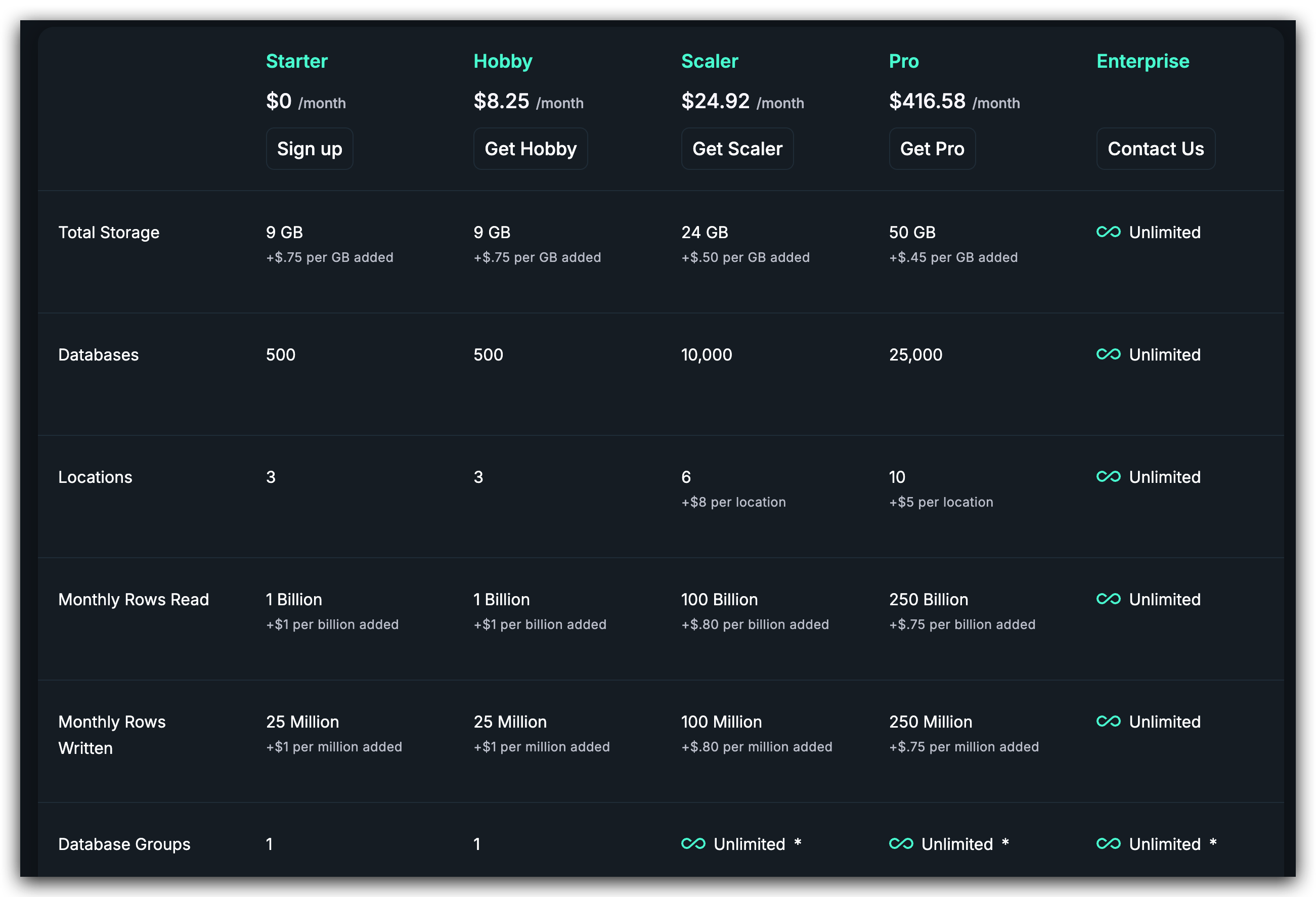
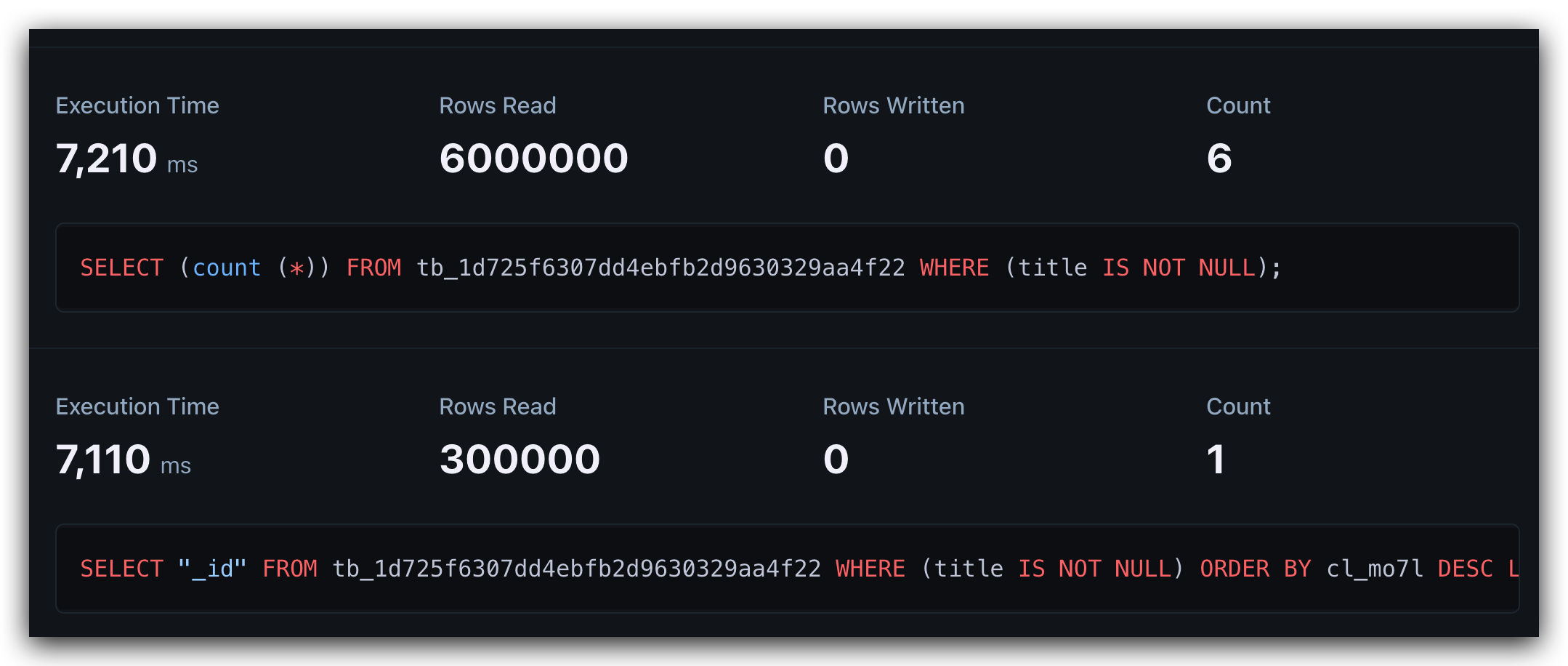
free plan 每个月 10 亿行的读取,看似非常多。我开始也这样认为,直到我上传了一个拥有一张百万行记录表的数据库。做了几次简单的 count 操作就消耗了几百万读取。当我还在为百万行的查询效果感到满意时,不知不觉已经快耗尽了额度。
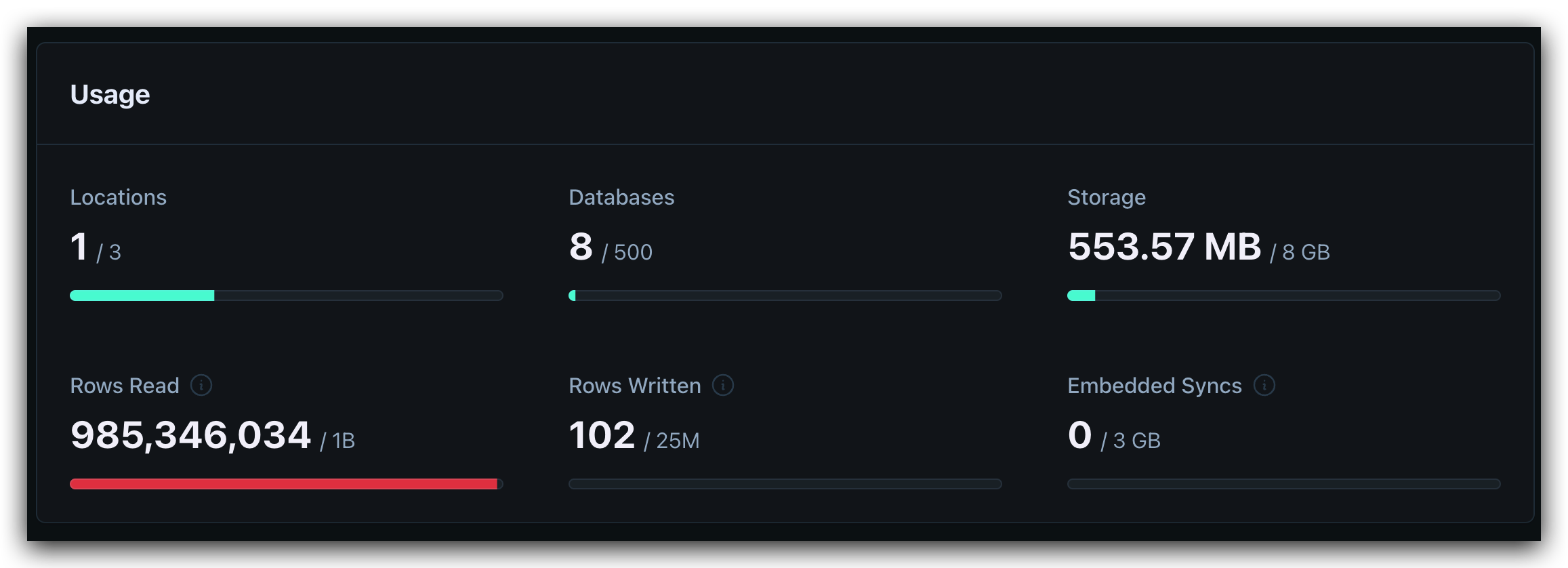
一百万的表,count 一次就会读取 100万行记录,6 次就是 600 万。只是我一个人访问随便折腾了下,额度就没了,这实在不是一个划算的方案。
我的想法是提供一个官方的服务,方便小白用户直接一键发布。对于开发者或者极客用户,可以按照教程,用自己的账号白嫖这些云厂商的 free plan,本来以为是足够个人使用的。结果不是很理想,当然这和数据量有关。如果发布以文档为主和小数据量表的 space,turso 是可以胜任这个任务。我也不是抛开“剂量”不谈,下面就来谈一谈“剂量”的问题。
数据量
Eidos 是服务于个人的,可能你会认为,一个人怎么会产生百万行级别的数据库表。这取决于你怎么定义个人数据。如果你只是记录你消费和创作的数据,每天写写日志,不管是你消费的书籍,歌曲,影视作品,还是发布的博客文章,毕竟个人的消费和生产能力有限,单表上万行可能就是极限了。但是当你整理数据时,这个数据量会变得很大。比如你订阅了很多 RSS 源,一堆 bookmark,又比如做一些 research 项目,用爬虫爬取了很多数据,这些结构化的信息,往往数据量都很大,这种算个人数据吗?可能不算,但是有发布的需求吗,还是有的。
我前段时间在做老头环的数据挖掘,解包产生了很多数据,1w 多条 NPC 对话文本和音频。 我想把这个表分享出去,对于一些热衷环学又不懂技术的爱好者来说是很友好的,一个可交互的多维表,方便做查询和预览音频资源,这就是我最开始的需求。 1w 行的表,在 100 个访问者的折腾下,也会出现几分钟就消耗1个月额度的情况。 尽管可以通过 cache 缓解数据库消耗,但是 Eidos 发布出去的表是可以给访问者自定义查询条件的,这样才能发挥其价值,这也导致了缓存命中会很低。
除此之外,随着时间推移,数据量是会增长的。Eidos 希望做一个长期项目,就如同口号里面提到的,管理一生的个人数据,因此需要考虑大数据量的问题,在各种实现的消耗上,我希望它是最优的。
小结
D1 和 Turso 是相同的计费模式,按读写行计费的模式会导致后期数据库变大时,耗费会越来越大。还是和场景有关,发布个人博客、wiki 这类 space ,是完全够用的。
这里顺带提一下一些体验上的细节。turso 的 cli 允许你直接指定一个 SQLite 文件上传,Cloudflare D1 则需要你先将 SQLIte dump 成 sql 语句,再上传,并且还需要手动做一些 sql 的兼容处理,整体体验比较差。turso 也存在 10m 大小的响应数据查不出来的情况,但整体体验还不错。
目前在 sqlite 云服务这块,Turso 和 D1 算的上是第一梯队,整体体验下来 Turso 要优于 D1 。
SQLiteCloud
https://sqlitecloud.io/ 是另外一家提供 sqlite 托管的云服务。他不是 turso 和 d1 那种 serverless,而是会给你开一 node,限制节点的物理资源。大抵还是虚拟资源的那套玩法,free 版本给的资源很少。我传了个 10w 行表的数据库,可以正常工作,但是 100w 行表的数据库直接卡死,节点重启了。服务还是早期,也没看到付费渠道。
这家除了提供 SQLite 托管,似乎也在测试和 SQLite + CRDT 的集成解决方案,可以期待一下。
Supabase
我甚至尝试了下 Supabase 。他本来是 postgresql 的解决方案,我想把 sqlite 转化为 postgres。幸运的是 pg 社区确实生态好,pgloader 可以完成这个任务。不幸的是存在一些兼容性问题,我并没有如愿以偿的将百万行的表导入成功。
Supabase 有个缺点是 REST API 不支持直接 sql 查询,它提供的 sdk 只支持你访问固定 schema 的表,所以最后还是放弃了。
Cloudflare Worker(Python)
cf 提供了 d1 作为数据库的解决方案,worker 的 runtime 里面也没啥可用的 lib 支持对 sqlite 的处理。我意外看到了 worker 的 python 实现,恰好在支持列表中 sqlite3 这个标准库可用。那我是不是可以把 js worker 无法实现的想法,用 python 实现呢。想象很美好,现实很残酷。本地 dev 没啥问题,部署一堆坑。结果是不可用。
其实也可以预料到,worker 对其他语言的支持,都是 build 成 wasm 产物,最后还是跑在 V8 的 runtime 下。该有的限制还是存在。我只期待 sqlite-wasm 什么时候能直接在 cf worker 中运行,但这似乎不太可能(如果支持了,那 D1 这个产品线怎么卖😂)
越是使用 Vercel、Cloudflare 这种平台服务,就越会感觉到其局限性。边缘计算的性能是无法言说的痛,什么 Edge Function 超时,这个库不能用,那个包不能引,并且限制在 js 生态中。但是这类服务的 DX 确实是最好的,链接 github 项目,一键发布,推送更新自动重新部署,这些体验都非常现代化和便利。
算是一个小插曲,最后还是得自己实现。
DigitalOcean
我开始意识到,serverless 并不总是满足需求和划算了。起码在 sqlite 云服务这块,到目前为止整个市场都还是处于早期阶段,并不像传统的 DBMS 云服务那样成熟。本来需求就很简单,自己写一个,我用 bun 实现了一个将 sqlite 转化为 api 的服务。
到了部署环节,我选择了 DigitalOcean,这种数据和计算密集型的场景,部署在 vps 中更加划算。印象中 DigitalOcean 和 Vultr 是卖 vps 的。没想到的是 DigitalOcean 给了我一些惊喜。得益于 docker k8s 的发展,DigitalOcean 也支持部署 app 了,类似于 https://zeabur.com/ 的玩法。整体体验下来,感觉比 zeabur 更加丝滑。读取 github 仓库,自动识别项目类型,是前端项目,还是 docker,还是其他项目,甚至扫描你的代码,知道你部署在哪个端口,然后自动域名映射过去,不用处理 https 的证书问题。整体部署体验和 vercel、cf 类似,但是区别在于,这种平台不限制你的技术栈。
Bun
接下来是 bun 的坑,DigitalOcean 将项目识别成了 node 项目,所以不得已,将其打包成 docker image 部署。
选择 bun 是因为 node 生态找了一圈 sqlite 的库都不太行,要么是底层暴露的 API 能力不足,要是接口设计品味的问题。新版的 node 也支持了 sqlite3,但还是选择了 bun,bun 的性能是最好的,接口设计也比较简约。
先聊下思路,再聊坑点在那里。 用户发布 space 时,除了 files 上传到 R2,现在把 db.sqlite3 这个文件也传到 R2。然后当用户访问发布的站点时,触发 sql 查询的接口,如果 sqlite server 机器上没有找到对应的数据库文件,会从 R2 拉取下来放在缓存文件夹中。 我个人的 space 使用了两年,数据库也才 30m 的样子。服务器带宽很大,很少有用户会有几百 M 的 sqlite,即使是几百 m 的 sqlite 下载也很快。这里有个冷启动的过程,如果某个 space 经常被访问,属于热点数据,那么在 sqlite server 中也会一直存在,对于访问较少的数据库则会清理掉文件,等待下次访问再启动。采用一个 LRU 的 pool 维护,这个 server 很简单。
还有一些把 S3 作为 vfs 的玩法,但是都偏 POC,会有性能问题,不作考虑。bun 为了提高性能,做了很多优化,野心很大,bug 也很多。比如从 R2 拉取大文件会直接报 out of memery。
价格对比
到此为止,我依然没有成功发布百万行表的数据库(turso 算是成功了,但是计费顶不住)。解决完 bun 的 bug 或者换个语言实现,应该就没啥问题。但是现在我的关注点已经不在实现 Publish 这个服务,而是云服务太贵了。
在 DigitalOcean 这个平台上,1 GB RAM | 1 vCPU | 150 GB bandwidth 配置的 app 实例一个月要花费 12刀,app 实际上是 docker 容器。这个价格如果换成 vps 实现,能获取更高一些的配置,但是相应的,你得自己处理 https 证书,docker 部署等相关问题。
让我们看看 12 刀/月的预算,你能获得什么。
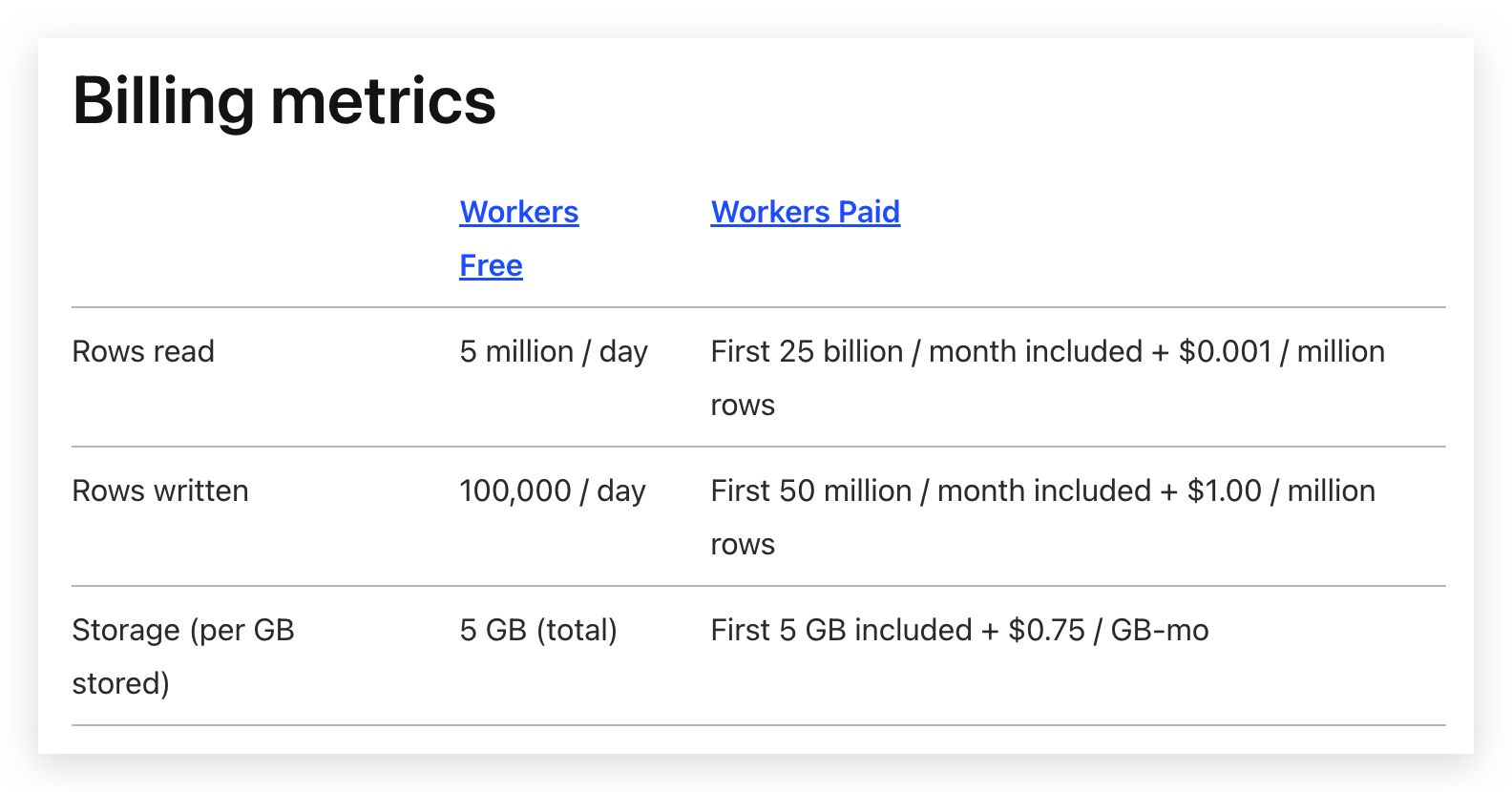 在 Cloudflare 提供的 D1 里面,你可以买到 15g 的存储+ 25b 次读取,50 b 次写入。请注意,这里的读,不是你一次请求算一次读取。举个栗子,如果你的表有 100 万行记录,一次
在 Cloudflare 提供的 D1 里面,你可以买到 15g 的存储+ 25b 次读取,50 b 次写入。请注意,这里的读,不是你一次请求算一次读取。举个栗子,如果你的表有 100 万行记录,一次 offset 900000 limit 5 的请求,实际会消耗 900005 的行读取次数。count 一次则会消耗 100万的行读取额度。
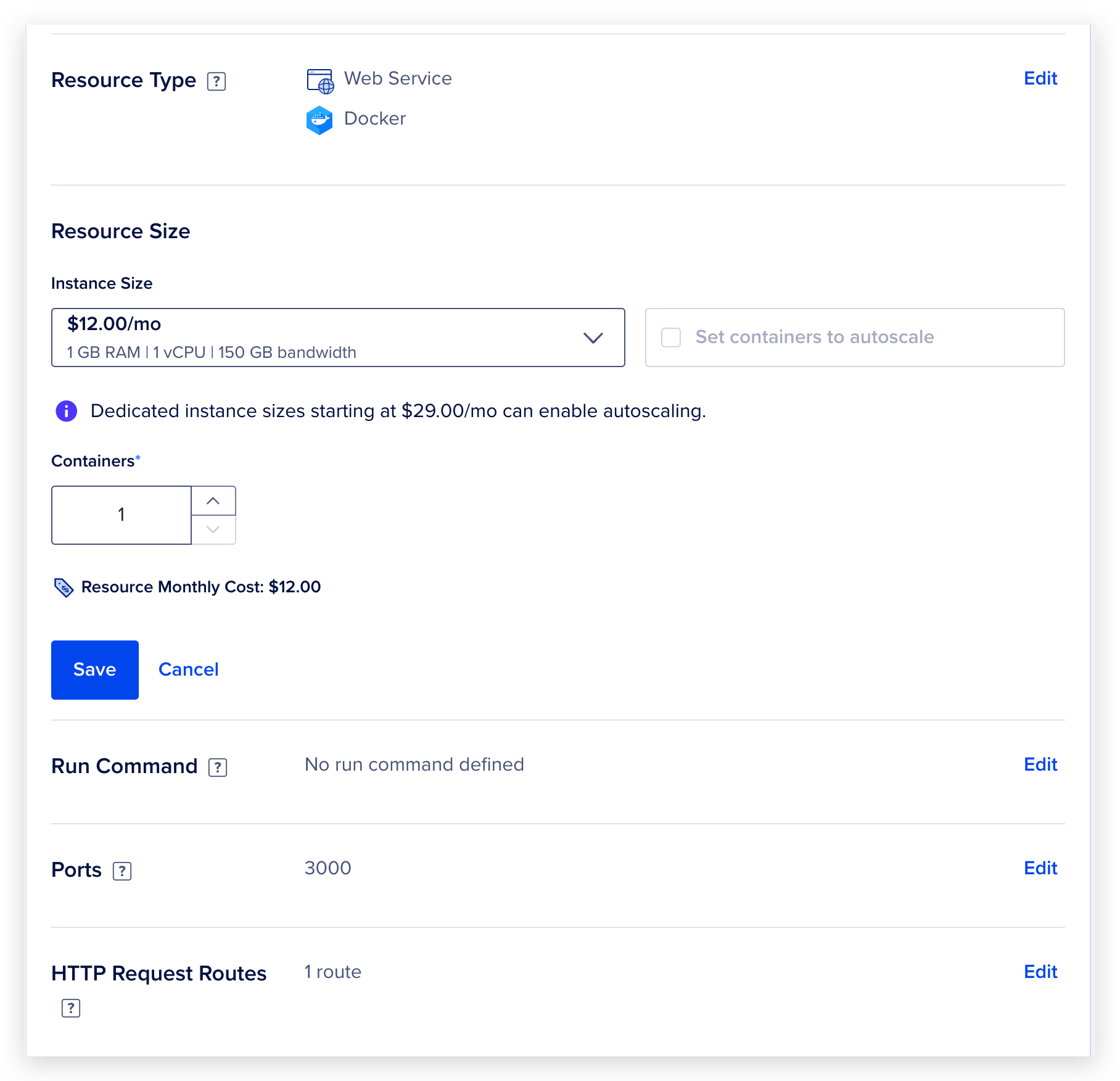 如果是 DigitalOcean 提供的 docker app, 你能获的 1核1 G RAM 150 gb 带宽的资源。
如果是 DigitalOcean 提供的 docker app, 你能获的 1核1 G RAM 150 gb 带宽的资源。
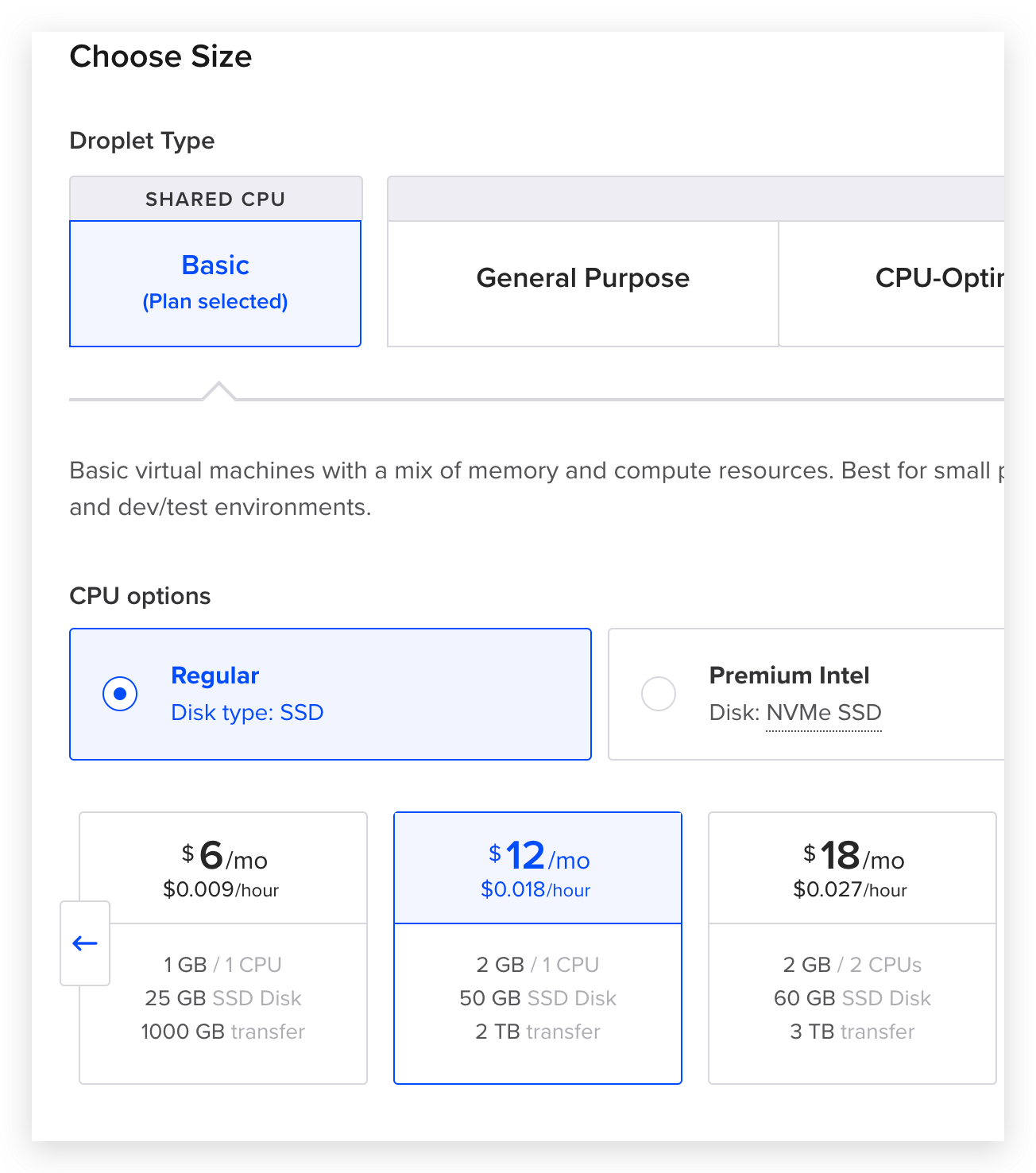 如果是 DigitalOcean 提供的 VPS,你能获取 1核 2G RAM 50G 硬盘 2T 流量的资源。
如果是 DigitalOcean 提供的 VPS,你能获取 1核 2G RAM 50G 硬盘 2T 流量的资源。

如果是 netcup 提供的 VPS,你能获得 12 核 24G RAM 768 GB 存储的机器。
加钱,世界触手可及
从最开始的 serverless d1 ,到提供现成 sqlite 服务的 docker 容器,再到自己实现的 docker 镜像部署,再到自己处理 vps 的部署,整个流程下来,你离物理机器越近,性价比越高。但是随之而来的是 devops 投入越来越大。但是你掌握了 docker k8s 这类工具,将部署过程做成自动化,也只是写一次,随后就能复用。
开发者可能会有个幻觉,docker 这样的虚拟化技术让运维对资源分配粒度更加精细了,对资源的利用率更高,所以 serverless 计费很精准,价格会越来越低。实则不然。每一层抽象都会附加增值服务,想要 github 仓库自动部署吗?想要漂亮的监控仪表盘吗?想要和同事协作管理集群吗?想要权限控制吗?想要更好的客服支持吗?全都得加钱。DigitalOcean 甚至还有专门的开发者套餐,然而花钱只是为了获取更好的客服支持。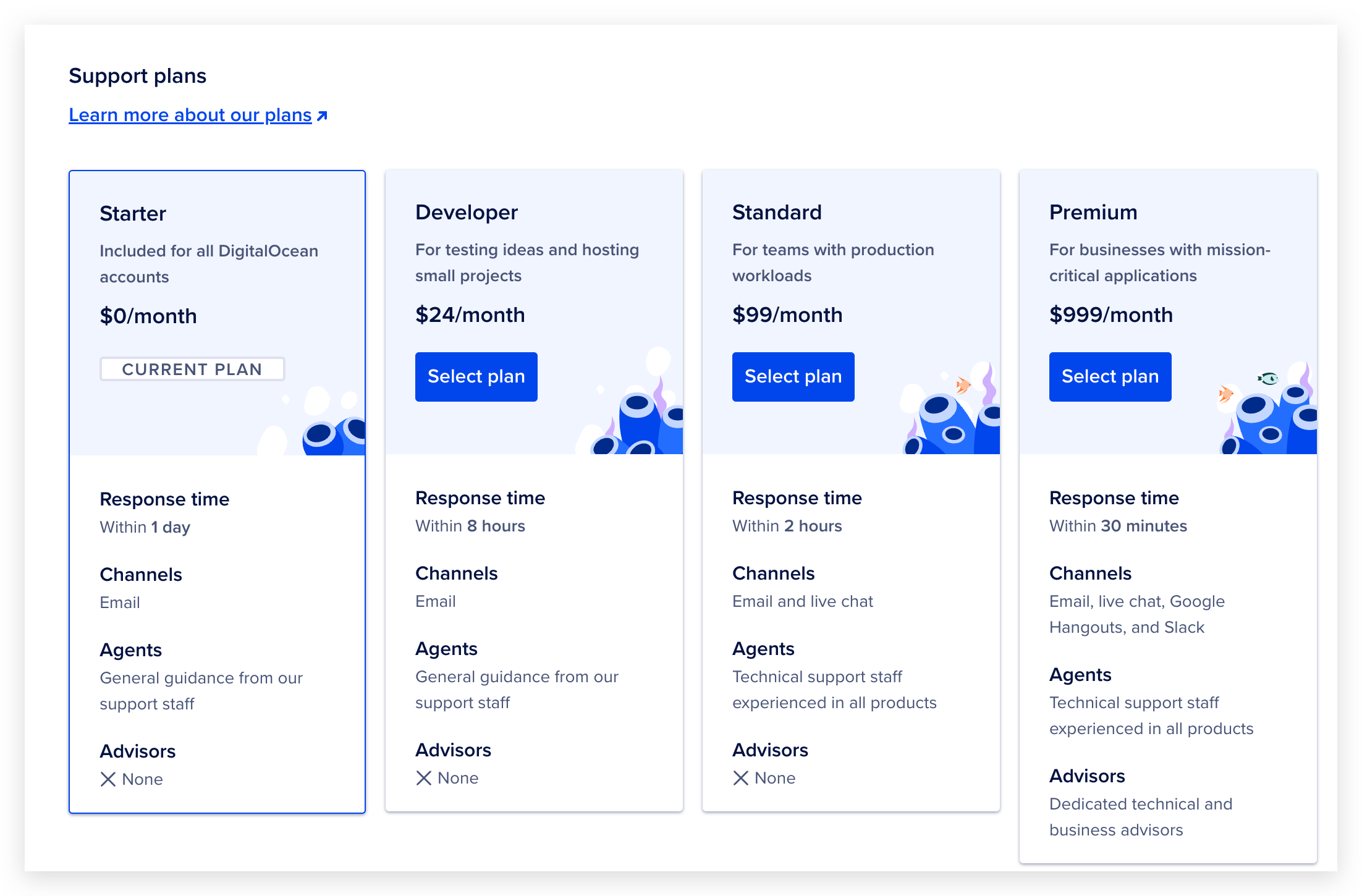
这有点类似于,下馆子、点外卖和自己做饭的区别。有很多只卖机器的服务商,他们的价格远低于 DigitalOcean。一些 PaaS 提供的机器性价比太低,因为他们附带了一堆增值服务,和只卖裸机器的服务商对比,同配置机器的价格差距可能高达 50 倍,你想想钱都花到哪里去了。
现在很多上层应用的 SaaS 服务都采用订阅制,但不是 pay as you go 的模式,这和你交水电费是完全不一样的体验,而是一种类似于买保险的商业模式,大部分的资源是头部用户消耗的,比如百万粉丝的账号和10粉丝账号,发布一条消息,推送成本是不一样的。但是平台不会要求百万粉丝的账号多交钱。付费用户花的钱,一部分是在为这种头部用户的消耗买单。
总结
Serverless,尤其是边缘计算的 serverless 难以处理计算密集型任务,这些任务通常是交给专业的 DBMS 处理,SQLite 做云服务的玩法还没普及开来。D1 和 Turso 在这一块处于领先地位,体验是很好的,但是开个奇怪的计费模式,可能在前期大家体会不到。这个计费模式,后面估计会被人诟病。
这和每个产品的实际需求相关,这类 serverless SQLite 提供了很多实用的功能,只是很多对于我当前的场景来说还用不上。在我的场景里面,只需要一个能将 SQLite 转化为只读的 API 计算服务,我并不需要那些额外的功能, backup、高可用等等我都用不上。
转而寻求自部署的解决方案,DigitalOcean 提供的 docker app 开发体验很好,但没有性价比,整个平台提供了太多的增值服务是我用不上的,却要为此付费,拿不到和付出成正比的计算资源。
越是上层的服务越是昂贵,每一层抽象都在附加增值服务。 当然这里并不是说 severless 不好,如果这些增值服务和你的需求契合,再好不过。 如果不契合,裸机器自己部署是性价比最高的解决方案,随之而来的是要自己处理 devops。没有好与不好,只有适合不适合。
凡事都有代价,加钱就能获得更好的服务,但是如果钱没花到点子上,这个代价最终还是会转移给终端用户。